Such a crazy time we’ve had over the last two years with us being made acutely aware of our mortality. Unlike some who could write a lot and be productive during this time, I could hardly write a blog post! (I could do Youtube cooking videos and discover gardening though). However, with life seemingly intent on bowling legspins and googlies (e.g. the Ukraine crisis) like the legenday Shane Warne who’s departed too soon, I think it’s time to revive the blog!
The major thing I did professionaly during the pandemic was change jobs and get promoted in the process – In October 2021, moved to Durham University Computer Science as an Associate Professor. The recruitment process froze during the middle of the pandemic (like normal life itself) but luckily the offer did come through a few months after the interview.
In that new role, I got the exciting opportunity of establishing a new research group as part of the rapid growth and restructuring of the department. We call this group NESTiD (Network Engineering Science and Theory in Durham) (happily, I suggested exactly the same name during my job talk :). The group first met informally in November 2021 with the first version of the website coming up in January 2022.
As maybe guessed from the name, the idea of the group is to explore hopefully fascinating research under the general umbrella of the network theme.
Our mission statement reads hence:
This is a broad-based research group with research foci including:
Network design and algorithms, Distributed and parallel computing and algorithms, Networked systems and applications, Security and resilience, Network science, Dynamism and processes on networks, Mathematical theory underpinning networks and communication, Social network design and human interaction, Cloud, edge, fog and wireless networks.
To recap, we were discussing the process of amnesiac flooding which can be viewed as possibly the simplest algorithm that can be executed in a decentralised/distributed manner on a network. Here it is described below, where M is a message/object/infection initiated by an origin node.
Let’s say, the flooding/infection happens in rounds. The amnesiac flooding process sends M to all its neighbours and then forgets about it (hence, the amnesia!). The nodes receiving M then clone copies of M and send to all the other nodes from which they have not most recently received M, and so on this process continue.
The main question we asked (and which we answered in our STACS2020 paper) was the following:
Does Amnesiac flooding terminate on every connected graph?
And here are the exercises from part 1 and their solutions:
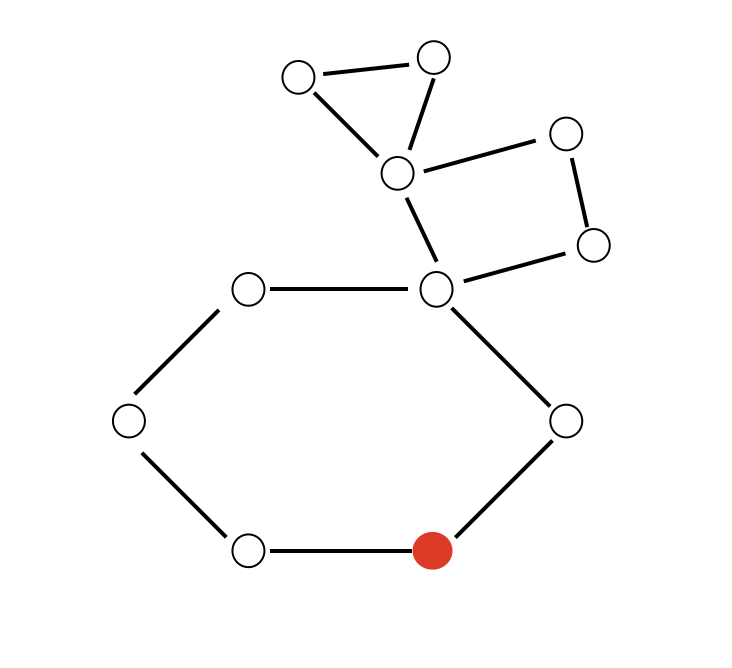
Exercise 1: Does Amnesiac Flooding terminate in the following graph (where it originates from the red node)? If it does, how many rounds does it take?
Well, here is the execution of amnesiac flooding starting from the red node (and we can count the number of rounds):
..and that’s 10 rounds. Good on you if you got that! Just for future reference, the diameter of this graph is 5. (For reference, the diameter of a graph is the longest distance (i.e. shortest path) between any two nodes in the graph).
Exercise 2: Going back to the Triangle and Square examples, how many rounds did it take for termination?
The triangle and square examples were in the first post. Here, they are again:
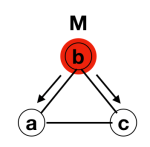
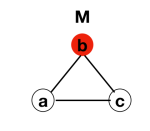
Node b transmits to both nodes a and c
Nodes a and c tranmit to each other
Nodes a and c transmit to node b
Process terminates at b
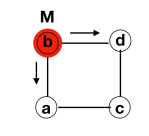
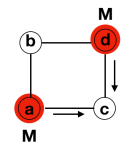
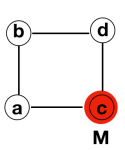
Node b transmits to both node a and d
Both node a and d transmit to node c
Node c just received from both neighbours so process terminates
Simple counting shows that it takes 3 rounds for termination in the triangle and just 2 rounds in the square. The intriguing thing is that the diameter of a triangle is 1 and that of a square is 2, but it takes longer for it to terminate in the triangle than in the square, Hmm, something odd here?
And here were the more difficult puzzles which are really research questions addressed in our paper:
Puzzle 1: A triangle has only 3 nodes and a square 4 but it still takes longer to terminate in the triangle. Any guesses why?
Puzzle 2: And the big question:
Does Amnesiac flooding terminate on every connected graph?
The answers are not at all obvious and there were no guesses in the comments section, so I have no idea what your first thoughts were, but here’s the answer 🙂 –
Yes!
i.e Yes, Amnesiac flooding surprsingly terminates on every connected graph i.e. wherever you may start on any graph, at some point, the messages cancel each other out.
Something even more interesting happens – the message (or, say, the infection) visits each node at most twice!! This immediately implies that the maximum time for the process to terminate is twice of the diameter (since if it was more then some node will be visited thrice).
Now, for the intriguing question of puzzle 1. Is there some relation between the diameter of a graph and the termination time of AF on it? But, then why does it not seem to hold for puzzle 1?
The answer lies in one particular property of the graph topology: bipartiteness! A bipartite graph is a graph which can be split into two sets of vertices such that all the edges go across the two sets and none between nodes on the same side. Now, if you observe carefully, a square is a bipartite graph. You can take the nodes which sit diagonally opposite each other in the same set and you observe that all the edges go across the two sets. In fact, any graph which is an even sized cycle (e.g. a square, or a hexagon) is bipartite whereas an odd sized cycle (triangle, pentagon) is not.
So, we get the following: If a graph is bipartite, amnesiac flooding terminates in at most diameter time (technically, in eccentricity of the origin node) with each node getting visited at most once! If a graph in not bipartite, the termination time will be more than the eccentricity of the node and less than twice the diameter, with each node visited at most twice.
Technically, the result is as follows:
Amnesiac flooding (AF) originating from a single node on a synchronous network terminates in a finite number of rounds. If the graph is bipartite, AF terminates in at most D rounds, otherwise in at most 2D+1 rounds, where D is the diameter of the graph.
For the technical details, see the paper, or await part-3 of this post!
At this moment, it is very difficut to write something without reference to the rapidly spreading Corona virus which has brought the world to its knees. As it happens, our recent paper (in STACS 2020) is about a network process which can be seen to resemble an extreme version of a viral spread. This process is network flooding for which we postulated an interesting natural question (Will this process ever stop by itself?). As a disclaimer, this is far from how a real virus may spread in a real network but it is a very useful algorithm for delivering something (messages or data in our case) to every node in a communication network.
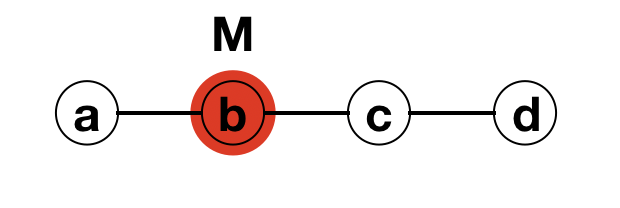
It is also a simple process to understand and a nice puzzle to attempt solving. So, let me postulate the puzzle and ask from you, the reader, a solution. To explain the flooding algorithm (which we technically call amnesiac flooding, as I’ll explain later) imagine the graph as given below. This is a simple line graph. The red node in the middle (node b) is the node originally having the message M (or the virus, if you wish).
Let’s say, the flooding/infection happens in rounds. The amnesiac flooding process sends M to all its neighbours and then forgets about it (hence, the amnesia!). The nodes receiving M then clone copies of M and send to all the other nodes from which they have not most recently received M, and so on this process continue.
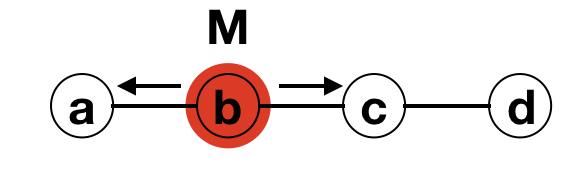
To illustrate on our line graph, this is how the process progresses:
Node b transmitting M to neighbours a and c
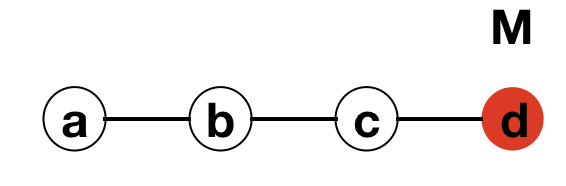
Node a has M but nobody to transmit to. Node c transmits to node d.
Node d has M but nobody to transmit to. Flooding terminates.
The illustration shows that starting from the single node b with the message/infection M, it sends M to nodes a and c. Since a has just received the message from b and it has no other neighbours, the transmission stops at that end. On the other end, c can still transmit to neighbour d, which it does. However, in the next round, d is the only one with M, but since it has just received the message from c, it has no neighbour to forward the message to. At this point, the process simply stops.
In the line graph it is easy to see that the process will stop (and quickly) but as soon as a graph has cycles, this is not obvious any more. In reality, a graph can be much more complicated with possibly many cyclic and acyclic components. So, the question we are interested in is as follows:
For any possible connected graph, will the flooding process (Amnesiac Flooding) terminate on that graph?
Note that, as mentioned, nodes do not retain a memory of having received M beyond the immediately last round. This is ike the character Leonard in the movie Memento, who has only short term memory but still has to accomplish his task. If the graph has cycles, it is quite possible that a node will receive M again and transmit it further again, and then again and again!
Amnesiac Flooding like the character in the movie Memento has only short term memory.
However, if the nodes had long term memory (like long term innoculation against a virus), all it needs to do to stop the message transmitting is to check the incoming message – if it is M, it just stops the tranmission. In fact, this is exactly how network flooding (which is probably the oldest and simplest algorithm for a network) has been usually implemented on real communication networks. However, this has a memory overhead over a longer series of floodings (nodes will retain these messages). Also, it is illustrative to study the memory/state-less variant which seems a natural propagation process.
Let us look at some simple cyclic examples and leave you with a puzzle for the part 1 of this blog post.
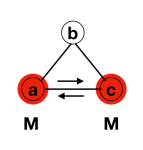
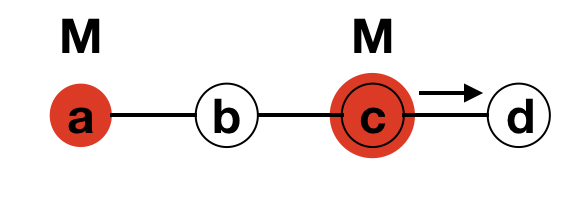
Node b transmits to both node a and d
Both node a and d transmit to node c
Node c just received from both neighbours so process terminates
Consider the graph which is a square. From the above figiure, we can see that the process terminates for the Square graph.
What about the Triangle?
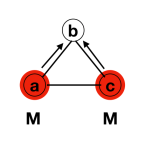
Node b transmits to both nodes a and c
Nodes a and c tranmit to each other
Nodes a and c transmit to node b
Process terminates at b
Again, the figure shows that it terminates in the Triangle. However, notice an interesting phenomena – the messages crossed over and were received multiple times.
So, here are the exercises and puzzles:
Exercise 1: Does Amnesiac Flooding terminate in the following graph (where it originates from the red node)? If it does, how many rounds does it take?
Exercise 2: Going back to the Triangle and Square examples, how many rounds did it take for termination?
Puzzle 1: A triangle has only 3 nodes and a square 4 but it still takes longer to terminate in the triangle. Any guesses why?
Puzzle 2: And the big question:
Does Amnesiac flooding terminate on every connected graph?
It will be great to see your answers/guesses in the comments below. I will come back with the solutions in part-2 of this post.
Recently, I received the good news that I am one of the recepients of the ASEM DUO-INDIAprofessors fellowship 2020, in partnership with Prof. Sushanta Karmarkar of IIT Guhawati. This is an innovative fellowship under the auspices of ASEM – Asia-Europe Meeting. The fellowship will allow Sushanta to spend one month with me in Loughborough and I one month visiting Sushanta at Guhawati, with the idea of developing our research!!
Overall, the ASEM DUO fellowship program fosters collaboration between European and Asian nations. Besides the professors fellowship, the DUO program also runs a similar exchange fellowship for students.
Disttibued algorithms and networks differ from their centralised counterparts in that failure is part of their DNA! i.e. they can continue despite failures and need to be designed to handle such failures. Failures can come in many forms – from crash failures (a component is knocked out and refuses to get up), transient failures (a component gets punched hard, falls down, recovers on wobbly feet!), Byzantine (a component (our fictitious boxer, as you have no doubt figured out by now) has taken money from bookies to fix the match and is trying to lose ruining the whole fight).
An adversary – the other boxer is a good way to model attacks – i.e. I seek to make a statement such that my boxer does well against the best boxer known; my boxer can stand forever against a boxer that does not use an undercut; my boxer does well against a boxer that throws random punches but may do poorly against one who knows that I didn’t have breakfast today;my referee does well against a bookie who’s paid my boxer to get the match fixed!
The paradigm which looks at keeping the distributed system running despite failures in some acceptable form (maybe degraded from the original) is called fault-tolerance. Self-healing is a fault-tolerance paradigm for reconfigurable networks, in a broad sense. Reconfigurable networks are networks which permit changes to be made quickly , say, in contrast with hard-wired networks where to change the network topology, you would have to physically disconnect and change wires. One example is overlay networks e.g the Internet which can be thought of as virtual connrections made over an underlay – a network of wirings which permit any two computers (say, with IP addresses) to connect to each other.
Self-healing can now be thought of as a game where an adverary removes/deletes/adds a node from the network/graph and the neighbours of the deleted node respond locally by creating new connections in the reconfigurable network with the objective maintaining global properties such as connectivity, distances, expansion etc while allowing only minimal increase in degree of individual nodes. Formalising and designing self-healing algorithms was the subject of my PhD thesis and this lecture should give some flavour of it.
The other topic this lecture deals with is compact routing – a very interesting topic that generated a lot of interest in the distributed graph algorithms community. Those with basic familiarity with routing will remember that to route messages in a network, two data structures are used: the routing table which is available at every node, and routing labels which are the address and related information that each packet contains. These can be thought of as corresponding to post-offices and addresses on letters to be delivered to individuals.
Now, the simplest way to biuld a routing table would be to run something like a Djikstra algorithm all pairs shortest path algorithm and at every node store which neighbour to forward a packet to for every destination. For example, if a node has three neighbours a,b, and c, and it gets a packet destined for node x, the node can see in its routing table that node b is on the shortest path from itself to x, and it can thus forward the packet to node b. This is called shortest path routing and is most desirable since it follows the quickest route to get packets across (ignoring other real world constraints such as bad weather, lazy porters etc etc..). However, the cost is that each node now stores an O(n) sized table where n is the number of nodes in the network. This is considered too much!
Thus, the research area of compact routing is obsessed with keeping the tables (and also the labels) to smaller (than n) size at the expense of approximating shortest paths – some thought on the matter leads to conclusion that this is an unavoidable tradeoff.
At the same time, what about the six degrees of seperation? – that idea states that not only do you know everybody in the world through a chain of six people, if these people were willing enough – they could even route a postcard from you to them! – thus, this is a really compact routing protocol. This effect was discovered by the Milgram experiment in the 1930s USA.
The difference is that this efffect relies a lot on geographical information i.e. Chicago is closer to New York than Albuquerque, thus, if I have a choice between a friend in New York and another in Albuquerque, I will send the packet to my friend in New York (i.e. I will do greedy routing) if my objective is to send the packet to a Barack Obama, resident of Chicago! In general, compact routing on networks has very little global information, thus, the challenge is higher. This information is gathered and a protocol built. This, however, creates a new challenge – what happens to the routing if the network changes. Compact self-healing routing is a research area that seeks to provide continuing compact routing when the network is changing, at least in the self-healing paradigm.
Elections are in the air!! – Oh well, that’s not much fun any more sadly so let’s do more mundane things like Computing!
Leader Election is one of the foundational problems of distributed computing – starting with a 1977 paper by Le Lann. The idea is for the nodes in the network to elect a leader among their own – no mean task even for computers!
Here, the drosophila of distributed computing comes into form – the Ring topology! We discuss some examples and algorithms on rings. Then we visit some of our own results – sublinear probablistic Leader elections on topologies like good expanders and the most simultaneously time and message efficient Leader Election!
We also visit verification and proof labelling – an attempt to understand complexity in distributed computing in similar terms to P vs NP centralised computing.
This lecture looks at the most basic of distributed algorithms: flooding (with a rather interesting question that arose accidentally!). We also see how it can be used to build spanning trees – Breadth First Search (BFS), Depth First Search (DFS) Trees, Broadcast and Convergecast (reverse broadcast)!
We look at the message passing model in a more formal manner including the timing model – synchronous or asynchronous! Thus, we fill up more of the empty slots of the huge matrix of possibilities of models in this multi-agent world of distributed computing!
A 180 degrees scene from DA@L – Distributed Algorithms @ Loughborough
Jan 28th, 2019 was a historic day at Loughborough University – well, at least, for distributed algorithms, since the first Distributed Algorithms @ Loughborough workshop was held there. Even though I am biased as the organiser, my feeling is that the day went well and the attendees enjoyed the workshop and all that was on offer – the high quality talks, the hospitality at Burleigh court – the large lunch and dinner, the drinks and even the foosball!
Somebody at Burleigh court kept trying hard to convince us (by putting up signposts) that our workshop was on Distribution Algorithms (rather than on Distributed Algorithms) but still the speakers pushed on with the high quality talks on distributed algorithms, the slides and abstracts of which are now available on the conference site www.cosher.org/dal or linked right below (in order of presentation). Many thanks again to all the attendees and to EPSRC for making this possible.
The first in a short series of lectures attempting the impossible task of covering distributed computing in 4 lectures to a group at the University of Bergen!
The Zoo of distributed computing where you’ll find many kind of creatures – regular or strange, benign or dangerous, dumb or rational and cunning, healthy or weak, quick or slow, boring or interesting. Centralised vs Distributed – Message passing (flooding etc) with a hint of Shared memory and PRAM etc.